AI will affect developers. But in what ways?

I’ve been asked to prepare a talk about the effect of AI on our IT industry and my immediate response was: as an AI language model (sic.) […].
First of all, as a technical guy I dislike a lot how the word “AI” is abused part of this hype cycle, so I promise not to mention it anywhere below this line. As Sam Altman twitted one of the few things I agree with him, AI doesn’t (yet) mean anything. It has yet to be invented:

When industry leaders speak of AI, they’re typically referring to large language models (LLMs) based on the Transformer Architecture. This architecture has revolutionized language processing with its vast training data, expansive network size, and parallel training capabilities. The real game-changer, however, lies in the attention heads — sub-networks adept at emphasizing crucial text segments, regardless of their position. The enigma of their effectiveness remains, as they process terabytes of data while sidestepping overfitting — a testament to the marvels of engineering, where functionality precedes complete understanding. Scientists will usually find an explanation afterwards, and entrepreneurs are building products with it way before that. I can’t recommend you enough Stephen Wolfram’s article on how LLMs work, and why, which is the best explanation I’ve seen so far: What Is ChatGPT Doing … and Why Does It Work?.
So how do LLMs affect developers?
Well, to start things off, we, the software developers are doing the thinking and the writing of “traditional” software, indeed with better and better tools. There are three distinct dimensions in which LLM can impact our work. First, LLMs can do the writing for us. This is what all IDE copilots are trying to achieve, and they are already doing it with great success. LLMs are in this sense autocomplete on steroids. With good prompting and good context, they can get it right most often than not, leaving the developer into a state of zombie brain pressing TAB after TAB in the hope of completing the job with minimum number of neurons firing — the copilot syndrome. Second, LLMs could do the thinking for us. Taking the autocomplete one step further, with properly written requirements, LLMs can generate the entire code, documentation and testing for a full feature. It’s what GitHub Copilot Workspace is currently promising in its limited release phase at the moment: Welcome to the Copilot-native developer environment — The GitHub Blog. This opens up some philosophical questions, first of which is: can machines think? to which Edsger Dijkstra, one of the founders of our field, answered in the ’80 in his famous “The threats to computing science” paper with the now famous quote: “The question of whether Machines Can Think… is about as relevant as the question of whether Submarines Can Swim”. This consequently opens another question: does programming require “thinking”, or is pattern finding and pattern matching enough? something we are certain artificial neural networks can do, and a level too deep maybe, how are “natural” neural networks different from artificial neural networks? aren’t we just responding to some inputs called stimuli using our brain’s f(x)? Is reductionism a valid strategy, and if we are built from atoms with deterministic behavior according to the laws of physics, we have no “free will” to actually perform “thinking”, we just compute inputs and output outputs? or is emergence something more than a word to hide our ignorance, something that can generate free will and thinking? Of course, this has nothing to do with the subject of this writing and it will be addressed separately, but it’s clear that some features could be implemented entirely by LLMs with no or minimum developer intervention. Third, LLMs could replace our code completely for certain applications. When fully deterministic, brute force algorithms are not an option, approximation algorithms can do the job just fine, as they have done it in the past (see Monte Carlo method). It has been already proven by Universal approximation theorem that any mathematical function (to be read by developers ‘algorithm’) can be approximated with any level of precision by a neural network. There will be multiple cases, due to the democratization of Machine Learning, where it would be more cost-efficient and “good enough” to use an LLM to approximate (and replace) an entire traditional software service. This would undoubtedly mean less thought, less code and less work for developers.
Two approaches as old as civilization
That was a bit much, let’s unpack it and start from scratch. Our thinking and writing code have one output, the “raison d’être” of our existence: algorithms. In a more generic definition, an algorithm is a function that takes some data x and turns it into data y.

As you already know, this is not an easy task. We put great effort and passion in this “arrow”, our careers, years of hard learned best practices, engineering methodologies, programming languages and paradigms, endless code review discussions, performance considerations, optimizations, mathematics, heuristics and lots of expertise. This process is one of my favorite topics and it’s what I enjoy doing for a living. If you want to go deeper, read my previous article on the topic: What we know we don’t know about algorithms.
The point is, there are two ways of transforming this data, of finding the f(x), and they are old as the civilization itself. Let’s go back in time two point five millennia or so, and let’s suppose our requirement is to build the Parthenon, the temple of Athena goddess. The requirements mention that it has to be 228x101ft or 69.5x30.9m. We need to draw the rectangle base, but how can we do it so that the angles are all square? Luckily, we just found out about Pythagoras recent writings in which he proved that for any right-angled triangle, the following equation must be satisfied:
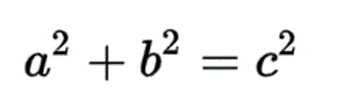
We have from our requirements a and b, we compute c, and we adjust the three sides on the ground until they form a triangle, until the other ends of a and b sides match the ends of the c side. We are now sure that our angles are squared, and the temple will last for millennia. In java, we compute c in one line:

This might seem trivial, but it is not. How many of you can implement the square root function by heart? Check this solution from JDK and think again: fdlibm/e_sqrt.c. This method of programming, fully deterministic, is tedious. It evolved from mathematics (Boolean algebra) and it is itself a temple build from previous knowledge which we now take for granted. It is an ever-growing field of knowledge to which we contribute every-day with newer algorithms build on top of existing ones. Most of our code it’s like that, or at least it used to be.
There is, however, a different approach to the hypotenuse problem. Let’s go back another 1000+ years or so in ancient Egypt, a place and time before Pythagorean formula was known, and let’s suppose our task is now to build a new pyramid, the biggest ever built by the Egyptians. The foundation should be a square with side of 756ft (230.3m) and our task is to draw the first measurements on the ground. Knowing the side, we just have to make sure we draw a square and not a rhombus, but not knowing the Pythagorean theorem it’s quite a challenging task. So, what can we do? What do Egyptians (supposedly) did? It turns out, they had determined, empirically, some pair of numbers that, when being sides of a triangle, always yield a right-squared triangle. Evidence for that is the ropes with knots found by the archeologists.
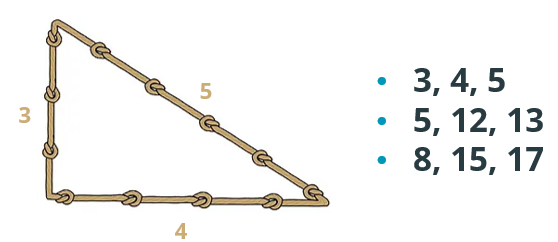
Their approach to this problem, and ours for that matter, is a data-driven one. Ignoring the irrational numbers problem, which was solved two millennia later, we now have a dataset of a, b, and c numbers that satisfy our condition (yielding a right angle). So in order to find the new c for our new a and b values, we need to hire an Egyptian data scientist that can take our dataset of empirically determined values and starting from a and b to predict the c, which is our hypotenuse. Now if we want to avoid the irrational numbers problem, we just use more rope, and pick a or b as the side of the square. The point is, this method is radically different from the previous one. We can’t be certain the results are 100% correct. But it can get us close enough to our desired objective, and it is a much faster way, and it requires less thinking than the previous analytical method. Moreover, it’s a technique that can be applied to almost any type of problem. If there is enough data, and there are patterns in the data, they can be discovered and/or approximated with the right configuration and neural networks architecture. By now, most certainly you got the idea that data driven method of problem solving is getting more traction, use-cases and piece of development pie due to the following two factors:
- Stakeholders expectations grew. The users of the apps we are building got more and more used to the power of data. While in the past the typical requirement was “Display the list of products and associated price, queried by the customer”, now we see more and more requirements like “Show me a prediction for the best discount I can set to this product to maximize sales profit”, which is exceptionally difficult to solve with traditional programming.
- Machine learning democratization. While in the past this use to be solely the job of data scientists, with tools like Auto ML and higher-level ML libraries, as well as LLMs which can already solve a lot of language specific tasks like sentiment analysis or classification out of the box, developers can integrate ML into their solutions by themselves or at least more easily than ever.
What we will do
It is already clear how new software will look like. At first, more and more solutions will incorporate neural networks for specific tasks, similar to currently ML powered apps, but the decision making, as well as program flow will still be developed by us:
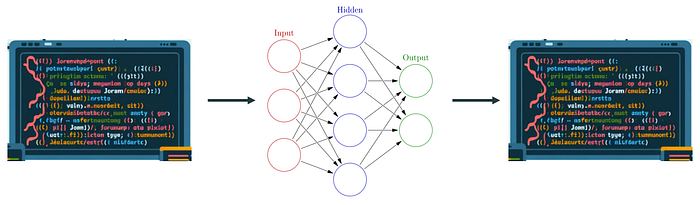
Subsequently, I expect we will work more and more on agentic solutions where the core decision making is assisted or decided entirely by an LLM type of system, and our traditionally written code will be mostly for tooling that will be used by such LLMs to access specific functions (API, legacy systems, proprietary protocols, etc):
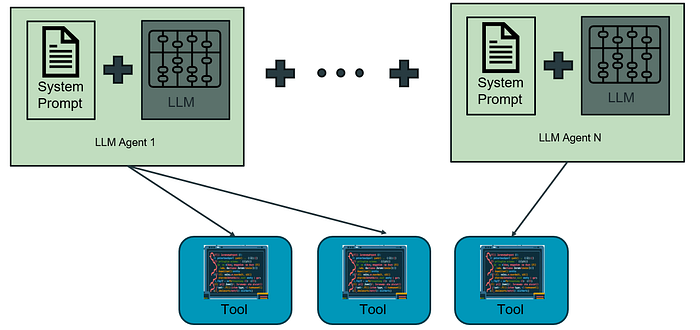
These systems will be harder to test, to maintain and to bug fix due to the inherent non-deterministic nature of LLMs. (yes, I know that technically LLMs are deterministic as they are “just” matrix multiplication, but without the randomness in the temperature, the results for text generation are much worse. Even without this, the fact that we cannot map every input to an output due to the sheer complexity of LLMs makes them difficult to handle safely in commercial software, let alone safety critical one).
So the software we work on will change, but not dramatically, and in some cases we will have less code to write and more parts to integrate. To build robust applications and systems which uses LLMs, our engineering best practices and methodologies will be even more important: we’ll have to pay more attention on costs, delays, resources, safety, testing, as all these aspects will become more difficult, but writing code will perhaps be less of an issue. It is an important but yet overrated aspect of a developer's job. We spend much more time reading code, thinking about scenarios, fine tuning for performance and readability, translating requirements and asking the right questions than coding anyway.
How will we do it
We’ve talked about the impact of LLMs on what we do, but how we do it is already impacted by the integration of LLM into our IDEs, where more and more code is generated for us, which is convenient to say the least. As a user of LLMs myself, I find it particularly useful when dealing with languages I’m not proficient in already. In my case, I write the java code I’m thinking at faster than I can prompt an LLM to write it for me, but if I’m writing in Rust or Go, then LLMs are a great help to find the right syntax or libraries for the job. The major limitations that I currently see for LLMs, and the reason I’m not (yet) afraid they will take my job in the near future, are the following:
- Tasks that require a deep understanding of the field. LLMs take shortcuts, they tend to use the more common scenarios in the training data more often than not. For complex tasks, in order to get a good response your prompting needs to be very well defined, which can be more difficult than implementing it yourself.
- Generating code style. Most of the code out there, no offence, is crap, and it’s part of training data. If you want efficient, well written code, corporate gold standard level, it’s unlikely you will get it (now) from an LLM. You’ll have to ask it to redesign it, to use certain design patterns that make sense, and so on. This can and I’m sure will improve in future LLMs but for now, it’s not straight forward to integrate LLM generated code.
- Context size. Yes, it improved a lot in recent models. You can almost fit an entire software project into one prompt. But do you want to do that for each code change? the more context you provide, the greater the chances for a good response, but also the higher the response time and the costs. At some point, it’s faster and cheaper to write it yourself. Micro-services for the win here. What is the best size for a microservice now might have a proper response: what can fit cost-effectively in an LLM prompt for automatic changes/bug fixing.
- Those services will have to be designed, planned and reasoned about. The current biggest disadvantage of LLMs is their limited reasoning abilities. LLMs weakest point is good developer's strongest point: reasoning abilities. It is this point that I’m most confident on. I tend to lean on the side that a big architectural change is needed so that AI (and now I’m using this term because we don’t know how this system will look like as it doesn’t exist yet) will gain the ability to reason well enough to beat us. On this topic, I’m on Yann LeCun’s side with regards to the future of Artificial Intelligence. I believe the path to AGI is not a bigger LLM (but I might be wrong and OpenAI or other can prove us wrong. Maybe more compute and parameters IS all we need, besides attention).
- LLM tendency to false positives. Being trained to be useful, they don’t like to say “I don’t know”, so they fabricate a lot of false positives. LLMs give a lot of valuable information from the training data, which makes them useful. A positive is that they don’t often say incorrect information about what was in the training data (essentially the curated WWW). However, when they don’t have the information, they fabricate (lower left corner), and it’s up to us to have the knowledge to distinguish between true and false positives, with lots of tests or prior knowledge. This means, in my opinion, that you can’t be effective in a domain you don’t know with an LLM assistant, as distinguishing between the two is difficult.

Conclusions
This being said, I do believe that LLMs are a tool that should improve the productivity of the average developer and it can be an excellent teacher compared with your average mentor, given all the shortcomings I mentioned above. I expect we will have to review even more code in the future, much of it being generated by LLMs, and that the quality of this generated software will improve. As for the reasoning parts, I believe they will remain our responsibility until there’s a major design breakthrough comparable with the introduction of the Transformer architecture, yet I acknowledge that a lot of simple tasks don’t require such reasoning and could be done entirely by LLM agentic workflows working in a ReAct loop. I also believe learning programing languages will become less important than learning software engineering practices and methodologies, as developers can be assisted now to write programs reasonably well in any language by LLMs. For building good products, we will need less crafting and more engineering, due to the new challenges and the rising complexity of our software. Moreover, some parts of our software that can be reasonably well approximated by an LLM will in some cases be replaced by an LLM, so there will be less code for us to write and more complexity to manage, but most of the time stakeholders and product owners will opt for deterministic, more efficient, good old coding whenever possible, demanding better efficiency and time to market from us, and we will be expected to deliver it due to better tooling, made possible by LLM integration in the entirety of project the lifecycle. Take all of the above with the disclaimer of a humble software developer.
Let me know your thoughts in the comments and if you want more coding stories, check out: One Code design principle to rule them all and What we know we don’t know about algorithms.
