One code design principle to rule them all

This week I had the privilege of being on the IT Days stage, trying to make amends for the awful code I wrote along the years by sharing best practices in a very condensed 30 minutes format. I also found out that not all developers share the same opinion about how the code should look like. To me, this reflects a lack of maturity of our industry. I think we have a moral obligation to make this industry more scientific, as we have disappointed many other industries by promising them fully automated business processes that we often failed to deliver, causing their downfall due to our lack of professionalism, estimation skills, and quality standards. Since our work of art, deliverable and mastery is code, I believe that is where we should start to look for the problems and for solutions as well. At the same conference, Mark Seemann (@ploeh) / X (twitter.com) gave an inspiring talk concluding that TDD is the scientific way of writing code, with a nice philosophical detour. I think we can generalize; we should use the scientific method to settle our debates as well. Unfortunately, that task is too difficult for me alone, so I am at least trying to argue for good practices using the discord: the classical Socratic method.
Regardless of the fancy title we carry on our badges, and oh boy, here in Romania titles are still a thing, programmers fall into two types:

The fact that we do this job with so different mindsets: the code crafter perspective and the software engineer one, is both beautiful and another sign of a lacking scientific method in our approach. Some of us regard coding as a type of art where they freely practice creativity and see where their imagination is leading them, much like The Oracle. Others regard themselves as software engineers, applying techniques selected by rigorously measured metrics. Code crafters use asynchronous messaging while software engineers use JMS over AMQP 1.0. Only 10% of the conference attendees identify as code crafters, but I doubt that the rest are true software engineers, judging by the quality of the code in our repositories. Engineers should try to measure, to test, to continuously improve and standardize their practice. That’s a noble endeavor. Maybe, like in the movie Matrix, we need both. It could also be the case that when we figure out what standards and metrics our code must adhere to, there will be little room for creativity in coding. How much freedom for creativity does a construction engineer have when following a plan?
If the message from the plot image resonated with you as well then you felt that something is wrong with our IT world. Well, I have a theory about the root cause of this problem. We have been programming for a living for about 80 years. Coding has been a hot topic of discussion and research, especially in the past three decades, and I’m sure most of us are trying hard to excel at work, and we’ve studied a lot on the subject. We have mastered our programming languages, code design, refactoring, design patterns, and so on. Yet, our code as a whole is terrible. I can say that with a certain degree of confidence as I had the privilege of working on many projects and having access to lots of repositories, from the companies I worked for and from the clients of those companies. I’ve rarely seen good, quality design on projects larger than a few thousand lines of code. Having now tools like Sonar, which track every code smell, measure cyclomatic and cognitive complexity of the code, and even security risks, makes this even harder to believe. Somehow, we reject the truth when it’s right in front of us: our code is bad, and we fail to fix it.
Why?
Why do we write bad code? There are many possible reasons. Maybe we don’t know how to write proper code, because the number of programmers doubles every five years, and we don’t have enough time to learn from books, mentors, and experience. Maybe good developers end up too soon in management positions, leaving behind a gap in skills and knowledge. Maybe we stop when the code does what it’s supposed to do, out of convenience or laziness. We enjoy the dopamine rush of solving the problem, but we avoid the pain of making our code maintainable. Maybe LLM tools we are using like ChatGPT are not good at design, because they have a limited context window or they are trained on existing bad code. Maybe it takes too much time, energy, and brain power to write good code, and we are not willing or able to invest them. Maybe best practices are sometimes contradictory or unclear. What does single responsibility actually mean? How do we apply SOLID principles in different situations? Are they even valid principles in 2023? Maybe we are hardwired with imperative style programming, and we struggle to adopt other paradigms, such as functional or declarative. Maybe we don’t embrace a more meaningful purpose, focus on the business value and code towards that.
Therefore, I propose a new principle, and a new definition of done:
“Discover what stakeholders want and express it at the proper level of abstraction”
We now just need to define what the proper level of abstraction is. In my opinion, it’s not a hard thing to do. Our stakeholders usually give us User Stories that describe their desired business flows, which look like this:
Suppose we implement exactly what they ask for. Now we know just as much as they do, assuming everything works flawlessly. We’ve completed our task, we received our payment, but if someone questions us about the functionality of this code, or the logic of these business processes, we are clueless.

The problem is choice. The number of decisions in our code makes it impossible to formulate a few meaningful sentences about our work. And there are only a few stories so far. It’s not anyone’s fault. Humans are bad at conditionals. Our brains work with concepts, and as psychologists discovered, not too many concepts at once, just seven. If they are correct, this means that our level 1 cache memory has three bits, and we probably use one encoding for the null reference which the researchers know nothing about. That’s not a lot, but we have to work with what we’ve got. We have to work towards our strengths, so we invented programming paradigms like OOP and FP, design patterns and high-level programming languages to address these brain limitations. At this point, adding more functionality, thus more decisions, will be more and more costly, until at some point it will no longer be feasible. At that point we wait for that big rewrite of the entire software, and we declare it legacy. This is because we still have work to do. We haven’t turned the user story mess into a coherent, straight-forward business flows that can be explained in a few sentences. We lack the code design, which has one sole purpose: to manage complexity. Obviously, complexity cannot be decreased, as it is best measured by the total number of decisions our code has to take to fulfil the business task it has to. So just like risk, it has to be managed. The apparent complexity, often called cognitive complexity (at least by Sonar tool), can be decreased through code design, making the project maintainable, decreasing the curve of cost per feature added.
By applying code design to above requirements, our business flow should look like a cooking recipe: so straightforward that our grandmothers could read, let alone our business analysts, product owners or stakeholders. By doing that, we’re not only discovering the requirements, but we can also eloquently explain them to businesspeople, bringing clarity over our work and delivering more business value than simply executing what was asked. So we’re not doing it just for us, future readers of the code we write and for all other developers in charge of maintaining the code along the years, but also for the business we’re trying to automate.

We’ve now answered to the fundamental question of the code structuring:
- What is the proper abstraction level for our code?
- It is the level where the services that express business logic have no conditionals.
It is the level where the code is as easy to read as a cooking recipe, even if it’s not written in the language Chef. Objectively, that will minimize the cognitive complexity of the code base, which is one of the best ways to improve maintainability. Not the only one, though, as there are multiple facets of the code impacting flexibility towards change, most importantly modularization and decoupling, and immutability.
How?
We’ve now reached the controversial part. While most of developers agree the code should be clean and easy to read (with the exception of those participating to obfuscated code contests like The International Obfuscated C Code Contest), very few agree on the how part. As talk is cheap, let’s look at some code. The most basic conditionals you can have in your code might by a simple mapper:
public static MeasureType toMeasureType(Unit unit) {
if (unit.measureType().equals("TEMPERATURE")) {
return MeasureType.TEMP;
} else if (unit.measureType().equals("HUMIDITY")) {
return MeasureType.HUMIDITY;
} else if (unit.measureType().equals("PRESSURE")) {
return MeasureType.FORCE;
} else {
throw new IllegalArgumentException("Unknown measure type");
}
}This code is easy to understand, because it has no business logic and most of the things are already named: enumerations are named by default, and the strings are self-explanatory. There is however one more thing we can name: the association itself. We can do that in multiple ways, but as there’s no business logic, I prefer to use an enumeration for this.
enum UNIT_MEASURE_TYPE_MAPPING {
TEMPERATURE(MeasureType.TEMP, "TEMPERATURE"),
HUMIDITY(MeasureType.HUMIDITY, "HUMIDITY"),
PRESSURE(MeasureType.FORCE, "PRESSURE");
private final MeasureType measureType;
private final String unitMeasureType;
UNIT_MEASURE_TYPE_MAPPING(MeasureType measureType, String unitMeasureType) {
this.measureType = measureType;
this.unitMeasureType = unitMeasureType;
}
public static MeasureType measureTypeForUnitMeasureType(String unitMeasureType) {
return Arrays.stream(UNIT_MEASURE_TYPE_MAPPING.values())
.filter(m -> m.unitMeasureType.equals(unitMeasureType))
.findFirst()
.orElseThrow(() -> new IllegalArgumentException("Unknown measure type"))
.measureType;
}
}Now the association is handled by the enumeration, and each mapping has a name. It is slightly more code though, and a lot of developers might call this overengineering. I’ll leave that decision to you.
Let’s attack a more realistic use case. A production code modified to fit this exercise, satisfying all acceptance criteria:
public Response myBusinessProcessEntryPoint(MyBusinessObject myBusinessObject) {
if (myBusinessObject.state() == State.PENDING) {
throw new IllegalStateException("Cannot process pending object");
} else if (myBusinessObject.state() == State.LOCKED) {
if (shouldUnlock(myBusinessObject, this.userPermissions)) {
UnlockRequest unlockRequest = new UnlockRequest(myBusinessObject);
this.unlockRequestService.unlock(unlockRequest);
return new Response("unlock triggered");
} else {
processLockedState(myBusinessObject);
}
notifySubscribers(myBusinessObject);
return new Response("should not unlock");
} else if (myBusinessObject.state() == State.PUBLISHED && !myBusinessObject.subscribers().isEmpty()) {
notifySubscribers(myBusinessObject);
changeState(myBusinessObject, State.DONE);
return new Response("changed status to done");
} else {
recordCall(myBusinessObject);
return new Response("recorded call");
}
}Reading this code, I can confidently say that this is not the proper level of abstraction for a business flow. I have no idea what it does by reading it, and it took me one hour to understand it well enough so that I could transform it into a workable use-case. But I’m not the reference here. Does it pass the grandma’ test? Surely it doesn’t. The most dangerous thing about code like this, which I’m sure you’ve had your fair share if you are a programmer, is the fact that some developers get used to it. It becomes familiar. The only ones that can understand it, the ones who work on it daily, will be reluctant to refactor it after a while. They’ve learned it by heart.
Contrary to popular belief, one can refactor a code one doesn’t understand, just by applying techniques. Experienced ones will recognize fitting patterns, like state or strategy patterns that might be suitable here. Today we are not interested in that. We want to start from the principles: it should look like a cooking recipe. Why is it so hard to read though? It is the fact that the “when” something needs to happen is mixed with the “how”, the procedural steps for each case, and mixed with the “what”, data involved, which makes this code a mess. Often, refactoring means splitting those three concepts and naming them.
“Once you name the “demon”, it doesn’t look that scary.” — myself, a refactoring enthusiast.
The first condition in our business process is a validation:
if (myBusinessObject.state() == State.PENDING) {
throw new IllegalStateException("Cannot process pending object");Usually, this doesn’t belong in the business process, if we apply the fail-fast principle. We shouldn’t let invalid data reach our business processes. Maybe we can handle it when this object (hopefully an immutable one) is created.
Let’s see how many “when’s” we have. If we group them smart, we notice we have four of them, the last “else” being the default case. A simple extract method should reduce all the “how’s” to a single line of code: a method call. At this point, since we don’t exactly know what the code does, don’t worry about names, just do it. I ended up with this:
public Response myBusinessProcessEntryPoint(MyBusinessObject myBusinessObject) {
if (myBusinessObject.state() == State.LOCKED && shouldUnlock(myBusinessObject, this.userPermissions)) {
return unlockAndProcess(myBusinessObject);
} else if (myBusinessObject.state() == State.LOCKED && !shouldUnlock(myBusinessObject, this.userPermissions)) {
return process(myBusinessObject);
} else if (myBusinessObject.state() == State.PUBLISHED && !myBusinessObject.subscribers().isEmpty()) {
return handlePublished(myBusinessObject);
} else {
return handleDefault(myBusinessObject);
}
}Next step is to look at the nature of our conditionals, and instead of “how to do things”, let’s focus on “what needs to be done”. Expressing logic declaratively is a good way to understand the mechanics of the code, if you are refactoring blindly. The nice thing about this technique is that as soon as you are done, the names of your entities will mostly be self-explanatory, will come naturally.
The nature of the “when’s” and “how’s”:
The conditionals take the parameter object, plus some state field, and return a Boolean. They are, in that case, a BiFunction, more specifically, a BiPredicate, as the return type is always a Boolean, while the “how’s” take the parameter, the business object, and return a response, making them a Function from a to b.
All business logic is an association of when we need to do something and what needs to be done. An easy way to represent an association is a dictionary, or a Map in some languages like Java. Let’s put our when’s and how’s, declaratively, in a Map:
public Response myBusinessProcessEntryPointSomewhatEnhanced(MyBusinessObject myBusinessObject) {
Map<BiPredicate<MyBusinessObject, List<String>>, Function<MyBusinessObject, Response>>
businessProcessHandlers = Map.of(
(myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.LOCKED && shouldUnlock(myBusinessObject1, userPermissions1),
this::unlockAndProcess,
(myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.LOCKED && !shouldUnlock(myBusinessObject1, userPermissions1),
this::process,
(myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.PUBLISHED && !myBusinessObject1.subscribers().isEmpty(),
this::handlePublished,
(myBusinessObject1, userPermissions1) -> true,
this::handleDefault
);
return businessProcessHandlers.entrySet().stream()
.filter(es -> es.getKey().test(myBusinessObject, this.userPermissions))
.map(Map.Entry::getValue)
.findFirst()
.orElse(this::handleDefault)
.apply(myBusinessObject);
}This is now expressed declaratively, and if we ignore the Map initialization, our logic really has no conditionals. We navigate through our possible entries, select the first one that matches our “when” and we apply the business transformation, the “what”. Yet, for traditional OOP developers this code is in worse condition than when we picked it up. That is because we haven’t named anything. We are still failing the grandma’ test, as we are working with abstract functions instead of named things which all human beans can easily understand.
One way to name things is by simply give them names:
public Response myBusinessProcessEntryPointWithNamedThings(MyBusinessObject myBusinessObjectParam) {
BiPredicate<MyBusinessObject, List<String>> lockedAndShouldUnlock =
(myBusinessObject, permissions) -> myBusinessObject.state() == State.LOCKED
&& shouldUnlock(myBusinessObject, permissions);
BiPredicate<MyBusinessObject, List<String>> lockedAndShouldNotUnlock =
(myBusinessObject, permissions) -> myBusinessObject.state() == State.LOCKED
&& !shouldUnlock(myBusinessObject, permissions);
BiPredicate<MyBusinessObject, List<String>> publishedAndHasSubscribers =
(myBusinessObject, permissions) -> myBusinessObject.state() == State.PUBLISHED
&& !myBusinessObject.subscribers().isEmpty();
BiPredicate<MyBusinessObject, List<String>> defaultPredicate = (bo, up) -> true;
Map<BiPredicate<MyBusinessObject, List<String>>, Function<MyBusinessObject, Response>> bpHandlers =
Map.of(lockedAndShouldUnlock,
this::unlockAndProcess,
lockedAndShouldNotUnlock,
this::process,
publishedAndHasSubscribers,
this::handlePublished,
defaultPredicate,
this::handleDefault
);
return bpHandlers.entrySet().stream()
.filter(es -> es.getKey().test(myBusinessObjectParam, this.userPermissions))
.map(Map.Entry::getValue)
.findFirst()
.orElse(this::handleDefault)
.apply(myBusinessObjectParam);
}This doesn’t seem to help much. Neither is the enumeration trick that we did earlier, as we might want to use some state in our services, and enumerations are statically initialized, but in cases where we only have pure functions this is a valid strategy:
public enum MyBusinessProcessMapping {
LOCKED_AND_SHOULD_UNLOCK((myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.LOCKED && shouldUnlock(myBusinessObject1, userPermissions1),
MyService::unlockAndProcess),
LOCKED_AND_SHOULD_NOT_UNLOCK((myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.LOCKED && !shouldUnlock(myBusinessObject1, userPermissions1),
MyService::process),
PUBLISHED_AND_HAS_SUBSCRIBERS((myBusinessObject1, userPermissions1) ->
myBusinessObject1.state() == State.PUBLISHED && !myBusinessObject1.subscribers().isEmpty(),
MyService::handlePublished),
DEFAULT((myBusinessObject, userPermissions) -> true,
MyService::handleDefault);
private final BiPredicate<MyBusinessObject, List<String>> predicate;
private final Function<MyBusinessObject, Response> function;
MyBusinessProcessMapping(BiPredicate<MyBusinessObject, List<String>> predicate, Function<MyBusinessObject, Response> function) {
this.predicate = predicate;
this.function = function;
}
public static Function<MyBusinessObject, Response> getProcessingFunction(MyBusinessObject myBusinessObject, List<String> userPermissions) {
return Arrays.stream(MyBusinessProcessMapping.values())
.filter(m -> m.predicate.test(myBusinessObject, userPermissions))
.map(m -> m.function)
.findFirst()
.orElse(DEFAULT.function);
}
}There is though a better way to name things, and that is to create custom types with the associations we want. In this case, classes for each association:
public static class UnlockAndProcessStrategy {
private final UnlockRequestService unlockRequestService;
UnlockAndProcessStrategy1(UnlockRequestService unlockRequestService) {
this.unlockRequestService = unlockRequestService;
}
public boolean appliesTo(MyBusinessObject myBusinessObject, List<String> permissions) {
return myBusinessObject.state() == State.LOCKED &&
shouldUnlock(myBusinessObject, permissions);
}
public Response execute(MyBusinessObject myBusinessObject) {
UnlockRequest unlockRequest = new UnlockRequest(myBusinessObject);
this.unlockRequestService.unlock(unlockRequest);
return new Response("unlock triggered");
}
}Now we have a class with two thigs which are somewhat named: an appliesTo method, our “when”, and the “execute”, our “how”. I named this class a Strategy as this is just a variation of a well-known pattern but be free to select what fits best for your business case you are trying to solve. We still have two more issues here. Our appliesTo method has way to many parameters. As Uncle Bob used to say, no parameters is ideal. One is acceptable. Two is already one to many. My opinion is that three should throw a compilation error. Let’s create a new record out of that. The other thing is that we need a way to work with all our business strategies uniformly. We need an abstraction layer. That is an interface.
@Service
public static class UnlockAndProcessStrategy implements BusinessStrategy {
private final UnlockRequestService unlockRequestService;
UnlockAndProcessStrategy(UnlockRequestService unlockRequestService) {
this.unlockRequestService = unlockRequestService;
}
@Override
public boolean appliesTo(StrategyConditionDiscriminator discriminator) {
return discriminator.myBusinessObject.state() == State.LOCKED &&
shouldUnlock(discriminator.myBusinessObject, discriminator.userPermissions);
}
@Override
public Response execute(MyBusinessObject myBusinessObject) {
UnlockRequest unlockRequest = new UnlockRequest(myBusinessObject);
this.unlockRequestService.unlock(unlockRequest);
return new Response("unlock triggered");
}
}With that in mind, our business process now looks like this:
public Response myBusinessProcessEntryPointWithStrategy(MyBusinessObject myBusinessObject) {
List<BusinessStrategy> strategies = List.of(
new UnlockAndProcessStrategy(this.unlockRequestService),
new ProcessStrategy(),
new PublishedStrategy(new Publisher()),
new DefaultStrategy());
StrategyConditionDiscriminator strategyConditionDiscriminator =
new StrategyConditionDiscriminator(myBusinessObject, this.userPermissions);
return strategies.stream().filter(s -> s.appliesTo(strategyConditionDiscriminator))
.findFirst()
.orElse(new DefaultStrategy())
.execute(myBusinessObject);
}And with the magic of dependency injection, the strategies can be added by your IoC framework, so we have:
public MyBusinessEntryPoint(List<BusinessStrategy> strategies) {
this.strategies = strategies;
}
public Response entryPoint(MyBusinessObject myBusinessObject) {
StrategyConditionDiscriminator strategyConditionDiscriminator =
new StrategyConditionDiscriminator(myBusinessObject, this.userPermissions);
BusinessStrategy strategy = selectStrategy(strategyConditionDiscriminator);
return strategy.execute(myBusinessObject);
}
private BusinessStrategy selectStrategy(StrategyConditionDiscriminator strategyConditionDiscriminator) {
return strategies.stream().filter(s -> s.appliesTo(strategyConditionDiscriminator))
.findFirst()
.orElse(new DefaultStrategy());
}At this point, I would say that this business process passes grandma’ test. What does it do? It creates a strategy discriminator based on the business object and the application state (user permissions). It uses the discriminator to select the applying business strategy, and it executes that strategy. How many strategies do we have? Four. There should be cooking recipes all the way down.
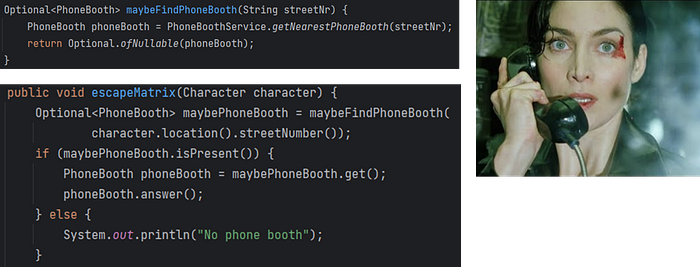
There’s one type of hidden conditionals we haven’t talked about: Optional values. They allow us to postpone the decision until we can use a default, or we can throw an error. So, there’s never a good reason to turn them back into an if statement, like in the example below.
Here’s what you should do instead:
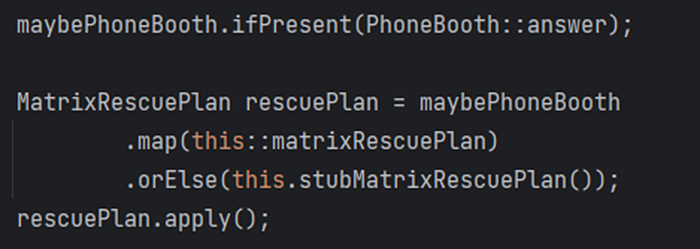
“If you can’t use a default behavior, you should probably throw an exception.” — Myself, on Handling Optional values
In conclusion, I believe that finding the proper level of abstraction is the most impactful principle for writing good software, but it is not the only one. The most important ones, which deserve their own article hopefully in the near future, are code decoupling and immutability. I would like to end with the most common arguments against refactoring approach described above and a refute for them. The first argument against refactoring is that writing more code increases the chances of introducing bugs. This argument assumes that more code means more data types, more classes, more methods. However, I believe this is a naive way of measuring code. The total lines of code is an unreliable indicator of error safety, otherwise we could claim that a totally obfuscated code is less prone to errors, which is obviously ridiculous. Two better metrics for measuring the code size are total cyclomatic complexity, which we can’t affect much (or at all depending on how it’s measured), as it’s a metric of the business functions our software fulfills and the decisional complexity. We can and should decrease the cognitive complexity of the code, which is another important metric that we can influence by design.
For code crafters who prefer more intuitive heuristics, I propose the grandma’ test, which in practice means to call the colleagues next to you that are working on a different project, and ask them what the code does, by measuring the time they reach a conclusion and the accuracy. Multiply that cost tenfold, as it will be read by many developers over the project lifespan. My bet is they all prefer the cooking recipe version, instead of counting the number of classes in the codebase. The second argument is about performance. First of all, performance is a concern that in 99% of the time is handled by system design, not by code design. Secondly, current day compiler optimizations are always a step ahead of us. Let’s focus on our job, and let the compilers do their thing, as they are doing it exceptionally well in this age. Third, if performance penalty of adding a new class, instantiating an object or calling some methods is too high, perhaps you are using the wrong programming language (maybe an interpreted one?) for the job. In either case, the cost of maintaining the code will surpass most likely other costs.
